| Issue |
J. Eur. Opt. Society-Rapid Publ.
Volume 21, Number 2, 2025
|
|
|---|---|---|
| Article Number | 40 | |
| Number of page(s) | 11 | |
| DOI | https://doi.org/10.1051/jeos/2025035 | |
| Published online | 12 September 2025 | |
Research Article
DKGCN-PCR: Deformable Kernel Graph Convolutional Network for Point Cloud Registration
1
Shijiazhuang Campus, Army Engineering University of PLA, Shijiazhuang 050003, PR China
2
77123 units of PLA, Mianyang 621000, PR China
* Corresponding authors: This email address is being protected from spambots. You need JavaScript enabled to view it.
(L.L.), This email address is being protected from spambots. You need JavaScript enabled to view it.
(Z.L.)
Received:
14
July
2025
Accepted:
12
August
2025
Abstract
We study the problem of feature extraction in point cloud registration. Traditional point clouds has the characteristic of irregular structure, which causes the neighborhood relationship that cannot effectively obtain point cloud data, and increases the difficulty of feature extraction in the point cloud registration task. This paper proposes a graph convolution point cloud registration network based on a deformable kernel. Compared with the non-deformable kernel, the proposed network is more suitable for irregular and unstructured point cloud data. Meanwhile, the network uses the semantic residual module to restore the lost local information and enhance the integrity of feature expression. The feature fusion layer integrates global and local features to enhance the model’s ability to express the features of complex point cloud data. We conducted tests on the 3DMatch, 3DLoMatch, and KITTI datasets to verify the effectiveness of the algorithm.
Key words: Point cloud registration / Graph convolution / Deformable kernel
© The Author(s), published by EDP Sciences, 2025
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
1 Introduction
The registration of point clouds is a fundamental task in the fields of 3D scene restoration, Simultaneous Localization And Mapping (SLAM), and remote sensing. The main task is to calculate the rigid transformation relationship between point clouds and convert the point clouds obtained from different perspectives and at different times to the same coordinate system. The mainstream schemes for achieving point cloud registration include direct registration methods [1–5], feature-based [6–8], and deep learning-based methods [9–18]. With the rapid development of deep learning, methods based on deep learning have made rapid progress in recent years.
The point cloud registration method based on deep learning is to learn the features of point clouds through deep learning networks, and then estimate the rigid transformation matrix between two point clouds by using methods such as RANSAC (Random Sample Consensus) and SVD (Single Value Decomposition) [9–18]. Traditional convolutional neural networks usually process point clouds after structuring them, and are more suitable for processing regular grid data such as images. Deep learning methods represented by PointNet [19] and PointNet++ [20] treat point clouds as unordered point sets, thereby avoiding information loss caused by structural transformations. Nevertheless, neither of them fully accounts for the relationships between points, resulting in notable deficiencies in local feature extraction. Specifically, PointNet adopts global maximum pooling operations, which makes it challenging to fully capture the local structural information of 3D point clouds. PointNet++ addresses the limitations of PointNet through a hierarchical design and density-adaptive mechanisms. However, its approach to utilizing neighborhood information is relatively fixed, leading to poor adaptability when handling complex local structures. In contrast, graph convolutional neural networks aggregate features by constructing graph structures for point clouds [21]. This enables them to better adapt to unstructured data like point clouds and thus more efficiently extract local geometric features. Based on this, this paper proposes a graph roll point cloud registration network based on a deformable kernel [22]. By using the graph convolution of the deformable kernel, the efficient expression of the local geometric structure features of point clouds at different scales has been achieved. Meanwhile, the network uses the semantic residual module to restore the lost local information and enhance the integrity of feature expression. Local features can be fused with global features and continuously updated, enhancing the model’s expressive ability for complex point cloud data. The main work of this article is as follows:
-
Three-dimensional graph convolution based on deformable kernels is adopted to break through the limitations of traditional convolution in processing irregular point cloud data. The kernel can adaptively adjust the shape and position according to the local geometric structure of the point cloud, achieving the translation and rotation invariance of the extracted point cloud features at different scales.
-
To retain the original feature information, a semantic residual module parallel to the graph convolution module was designed. This structure can not only capture the initial features of the input, but also learn the advanced features after multiple layers of processing.
-
The hierarchical fusion strategy is employed to fuse the global features with the local features at different levels. First, conduct the preliminary fusion of fine-grained local features and global features, and then gradually incorporate coarse-grained local features. The fused features take into account both the global and local features of the point cloud, greatly enhancing the model’s ability to express the features of complex point cloud data.
2 Related work
First of all, we briefly introduce the traditional point cloud registration methods, which can be divided into feature-based methods and direct registration methods. Then, we emphatically introduce point cloud registration methods based on deep learning.
2.1 Feature-based point cloud registration methods
Firstly, the manually designed feature descriptors are used to describe the point cloud features. Then, corresponding feature points are obtained based on the point cloud features. Finally, methods such as RANSAC and SVD are used to calculate the poses and obtain the point cloud transformation matrix. Common feature descriptors include 3DSC, PFH, FPFH, SHOT, etc [6–8].
2.2 Direct registration methods
The direct registration methods directly process and calculat the feature transformation matrix of the point cloud. Common direct registration methods include ICP (Iterative Closest Point), NDT (Normal Distributions Transform), and RANSAC. The ICP algorithm has a strong dependence on the initial value and is usually applied in the fine registration stage of point clouds [1–3]. NDT does not rely on the initial value like ICP [4, 5]. Even if the error is large, it can still complete the registration. However, the result may not converge to the optimal solution and is often used in the coarse registration stage of point clouds. The RANSAC algorithm is directly applied to the point cloud registration work without feature extraction [23]. If the RANSAC algorithm is used to register the original point cloud data directly, the amount of calculation is often large. In the absence of utilizing the feature information of point clouds, the RANSAC algorithm is unable to capture the correspondence between points, resulting in relatively low registration accuracy. Therefore, the RANSAC algorithm usually extracts features first and then performs registration.
2.3 Methods based on deep learning
Learning-based methods utilize deep learning networks for feature extraction. These methods reduce the dependence on point cloud feature descriptors in manually design and has less dependence on noise and data changes. Yasuhiro Aoki et al. proposed PointNetLK [9]. This algorithm modified the classical LK (Lucas-Kanade) algorithm and combined it with PointNet to adapt to the PointNet imaging function. When applied to the point cloud registration task, it has good robustness and performs excellently in terms of computational efficiency and accuracy. Yue Wang et al. proposed the DCP (Deep Closest Point) algorithm [11]. This algorithm applies the Transformer network to the point cloud registration task and realizes the information interaction between features. Both PointNetLK and DCP have proven that deep learning networks outperform traditional methods. However, their application effect in partially overlapping point clouds is not satisfactory. Yue Wang et al. further proposed PRNet [12]. By introducing the Gumbel-Softmax to determine the correspondence between sampling key points, registration of partially overlapping point clouds has been achieved. This approach outperforms PointNetLK, DCP, and non-learning methods on synthetic data. G. Dias Pais et al. proposed 3DRegNet [15], which leverages the powerful fitting ability of deep learning to address the problem of precise point cloud registration. It surpasses the accuracy of existing RANSAC and ICP methods and at the same time achieves a speed 25 times that of RANSAC on the CPU. Xiyu Zhang proposed a point cloud registration method based on the maximum clique [16]. Through an improved maximum clique constraint method, more local information can be mined, effectively improving registration accuracy. The combination with deep learning methods have also achieved remarkable results. Shengyu Huang et al. proposed Predator [17]. For point cloud in low-overlap area, Predator uses an overlap-attention block to exchange point cloud information. By accurately predicting the significant features of the point cloud in the overlap area, it achieves robust registration in low-overlap area. Sheng Ao et al. proposed BUFFER [18]. BUFFER effectively balances the trade-off between accuracy and generalization ability in the point cloud registration task by using point-to-point technology, face-to-face technology, and an internal point generator.
Feature-based methods focus more on local feature description. Direct registration methods are overly dependent on the initial values. In outdoor scenarios with low overlap rate and dynamic target interference, the robustness and accuracy of traditional algorithms are difficult to guarantee. Deep learning methods can fully explore both the local and global information of point clouds and show significant advantages in the above-mentioned complex outdoor scenarios. Therefore, this paper conducts in-depth research on point cloud registration methods based on graph convolutional neural networks.
3 Proposed method
Given two partially overlapping point clouds P = {pi ∈R 3|i = 1,…, N} and Q = {qi ∈R 3|i = 1,…, M}, the goal of point cloud registration is to find the rigid transformation matrix of the two point clouds and restore their alignment relationship. DKGCN-PCR is a graph convolution point cloud registration network based on a deformable kernel, and its network architecture is shown in Figure 1. Firstly, we use the graph convolution module of the deformable kernel to extract the point cloud features layer by layer. Then, point matching is performed based on the extracted features. Finally, the transformation matrix of the point cloud is estimated using the RANSAC transformation according to the point matching relationship. The feature extraction part of DKGCN-PCR mainly includes three main modules:
-
3D Graph Convolution Module. Each convolution kernel dynamically adjusts its shape and size according to the geometric structure of the local point cloud, thereby better capturing local features.
-
Semantic Residual Module. To retain the original feature information, a semantic residual module parallel to the graph convolution module was designed. This structure can capture not only the low-level features of the input but also the high-level features after multiple layers of processing.
-
Feature Fusion Layer. In order to enhance the model’s ability to express the features of complex point cloud data, a hierarchical fusion strategy is employed to fuse global features with local features at different levels.
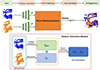 |
Figure 1 Firstly, perform feature extraction on the two groups of input point clouds to obtain the feature representations F P and F Q respectively. Then, the point matching module completes the point correspondence relationship mining based on the features. Subsequently, the RANSAC algorithm is used for pose estimation to solve the transformation parameters (R, T) (rotation, translation). Finally, the 3D registration of the two groups of point clouds was completed based on this transformation to achieve point cloud alignment. |
3.1 Three-dimensional graph convolution module
When processing image data with 2DCNN, since the image pixels are regular grid data, fixed-size convolution kernels can be used to extract local image features. Extending 2D image pixels to 3D space is the concept of voxels. The voxel, short for volumetric pixel, is a regular data structure in three-dimensional space. Compared to 3D voxel space, 3D point cloud data is characterized by its disorder and lack of structure, with no definite neighborhood relationships. When processing voxels using 3DCNN, global features are extracted through maximization pooling [19], but it is challenging to capture the local point-to-point relationships within the point cloud. Therefore, we introduce the graph convolutional neural network and construct the local graph structure relationship of the point cloud by calculating the nearest neighbors of each point. Then, we dynamically adjust the shape and size of the local point cloud according to its geometric structure to better capture local features. Figure 2 illustrates the schematic diagram of 3DCNN (Fig. 2a) and 3D graph convolution (Fig. 2b).
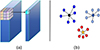 |
Figure 2 Schematic diagrams of 3D convolutional neural network (a) and 3D graph convolutional network (b). |
Different from the traditional CNN network, where the receptive field is defined through the convolution kernel in Euclidean space, the graph convolutional network in this paper uses K-nearest neighbor search to determine the local neighborhood set. First, calculate the normalized relative direction vector ri,j through the KNN search as: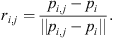 (1)
(1)
Among them, ri,j is shaped like (b, vertical_num, neighbor_num, 3), representing the direction relationship between the neighborhood point and the center point. vertical_num and neighbor_num respectively represent the number of vertices in the point cloud and the number of neighborhood points for each vertex. pi represents the center point, and pi,j represents the neighborhood point of pi.
For each point pi and its neighbor node pi,j, the similarity θi,j between its direction vector ri,j and the predefined support vector di,j can be expressed as: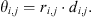 (2)
(2)
Among them, the predefined support vector di,j is a trainable parameter. During model initialization, it initializes the shape to (3, support_num, out_channel) through uniform distribution and is updated through backpropagation during the training process. Among them, 3 represents that each direction vector has three components, corresponding to the x, y, and z axes in the 3D space. support_num · out_channel represents the number of support direction vectors multiplied by the number of output channels, which determines the dimension of the support direction vectors.
In the graph convolution operation, by calculating the similarity between the receptive field direction vector and the predefined support vector, a similarity matrix is generated to weight aggregate the features of neighboring nodes. To ensure that all similarity values are non-negative, the ReLU activation function is applied to process the similarity calculated by formula (2), and a new value of 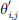 is obtained as:
is obtained as: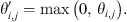 (3)
(3)
The initial features of the input to the graph convolutional network are extracted by KPConv-FPN. To better capture the features, a weight matrix and bias vector are introduced to map the input features and obtain a new feature map, which is represented as: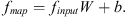 (4)
(4)
Among them, finput ∈ (b, n, in_channel) represents the input feature map, which is obtained through downsampling processing by the KPConv-FPN network. W is the trainable weight matrix, mapping the input features from dimension in_channel to dimension (support_num + 1 · out_channel). b is the bias vector, and finput ∈ (b, n, support_num + 1 · out_channel) represents the new feature map obtained after mapping.
The new feature map is separated into central features and supporting features. The first N dimensions of the new feature map are selected as the central features to represent the direct features of each point, which is expressed as: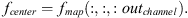 (5)
(5)
Among them, the central feature fcenter ∈ (b, n, out_channel) represents the direct features of each point, and these features are used as the basic features in the subsequent graph convolution operations. Central features usually contain local information of each point, and this information will be retained and enhanced in the subsequent feature aggregation.
Select the remaining support_num · out_channel dimension features of the new feature map as supporting features to represent the neighborhood features of each point, which are expressed as: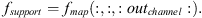 (6)
(6)
Among them, the supporting features fsupport ∈ (b, n, support_num · out_channel). By combining with the central feature, the supporting feature helps capture the structural information of the point cloud and enhances the model’s perception ability of the local geometric structure.
The similarity matrix obtained by formula (3) is used to weight the support vectors, and the activation support feature is generated and represented as: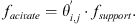 (7)
(7)
For each neighbor point, take the maximum value of facivate to generate the maximum activation support vector for each neighbor point as: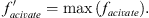 (8)
(8)
Take the average of the maximum activation support features for each point and generate the final activation support features for each point, which are expressed as: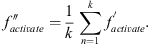 (9)
(9)
Add the central feature to the final activation support feature to generate the final vertex feature of the graph convolutional neural network, which can be expressed as: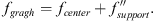 (10)
(10)
The predefined support vectors in formula (2) are learnable parameters. Therefore, the convolution kernels corresponding to the graph convolutional network model are no longer the weight matrices of fixed Windows, but a set of parameterized 3D direction vectors. By learning the direction vectors in different directions to generate deformable convolution kernels, the semantic extraction of the geometric structure of the point cloud was finally achieved in formula (10).
3.2 Semantic residual module
In Section 3.1, the semantic extraction of the geometric structure of point clouds was achieved through the graph convolution module. In order to retain the original feature information, this section designs a semantic residual module parallel to the graph convolution module. The input of the semantic residual module is the original feature extracted by KPConv-FPN, which undergoes a linear transformation through an independent one-dimensional convolution and can be expressed as: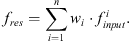 (11)
(11)
Among them, wi is the weight parameter of the one-dimensional convolution kernel, and 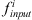 is the input feature at the ith position of the feature obtained by the KPConv-FPN network.
is the input feature at the ith position of the feature obtained by the KPConv-FPN network.
In the DKGCN-PCR network, the initial features extracted by KPConv contain the underlying information of the point cloud, forming the basis for subsequent feature learning. After KPConv completes the initial feature extraction, the semantic residual residual module introduces a convolution operation as shown in formula (11). The core purpose of this operation is to ensure the effective integration of the residual branch with the output features of the graph convolution module. To achieve this, it employs dimension adjustment and feature transformation while preserving key information from the original features. Then, the result of directly adding it to the features after the graph convolution operation can be expressed as follows: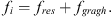 (12)
(12)
Among them, fi is the output feature of the ith point, fres is the semantic residual module feature after linear transformation, and fgragh is the feature obtained through graph convolutional neural network processing in formula (10). This structure is capable of capturing not only the low-level features of the input but also learning the high-level features after multiple layers of processing.
3.3 Feature fusion layer
In Sections 3.1 and 3.2, through the convolution operation of 3D point cloud maps and the residual module, we obtained the most significant features within the neighborhood of each point. Then, we use the KNN search method to select the nearest k points by calculating the Euclidean distance between the vertices. According to the neighborhood index, we obtain the neighborhood features of the vertices. Specifically, for the ith vertex, extracting the features of its k neighborhood points can be expressed as: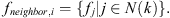 (13)
(13)
Among them, N(k) represents the k-nearest neighbor index set of vertex i, and fj represents the features of vertex j .
The neighborhood features of each point are aggregated to obtain the feature representation of each vertex. The features are aggregated using the maximum value method and expressed as: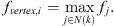 (14)
(14)
Average the features of all vertics to obtain the global context features, which can be expressed as: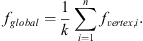 (15)
(15)
The vertex features obtained by the graph convolutional network are stitched together with the global context features. This process yields concatenated features that integrate vertex features and global features, which can be expressed as: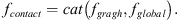 (16)
(16)
The feature dimension of fcontact is adjusted through convolution operation and added to the feature fgragh obtained by the graph convolution.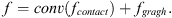 (17)
(17)
Among them, fgragh represents the local feature of the vertex, which can capture the neighborhood information of each vertex. conv(fcontact) represents that the global feature, which can provide the context information of the entire point cloud. The final obtained feature f is the fusion of global features and local features. The influence weight of the features of the most reliable vertices on global feature extraction can be increased through the maximization method of formula (14). The extraction of global features guided by local features was achieved through formula (15), which can minimize the influence of noise introduced by local features to the greatest extent.
By applying the hierarchical fusion strategy, global features are fused with local features at different levels. Firstly, the initial fusion of low-dimensional local features and global features is carried out. Then, high-dimensional features are gradually incorporated. The final feature ffinal obtained can be expressed as: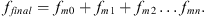 (18)
(18)
The fused feature ffinal is updated through the deep learning gradient descent mechanism. In point cloud registration tasks, the effectiveness of such features directly depends on their ability to capture both global and local information – a challenge rooted in the unique nature of point cloud data.
Point cloud data is characterized by being unordered and unstructured. Relying solely on local features may lead to getting stuck in local optimization due to the lack of global context constraints. Conversely, relying exclusively on global features will result in the loss of key details, making it difficult to capture fine-grained geometric correspondences in the point cloud. Therefore, integrating global and local features provides a more comprehensive feature foundation for point cloud registration. Specifically, global features act as prior knowledge, guiding local features to focus on geometric information consistent with the global structure. Local features acquire neighborhood features through k-nearest neighbor search and are aggregated via max pooling, thus retaining the fine geometric details of the point cloud. Through a hierarchical fusion strategy, local features at different levels are gradually integrated into global features, enhancing the expressive power of multi-scale features. These operations ensure that global features can accurately reflect the overall structure in complex scenarios while avoiding the loss of key local information. The final fused features comprehensively take into account both the overall and local characteristics of the point cloud.
4 Experiments
4.1 Dataset
To test the effectiveness of the DKGCN-PCR algorithm on real point cloud data, we selected the indoor datasets 3DMatch and 3DLoMatch, as well as the KITTI dataset, which represents large outdoor scenes. Among them, 3DMatch comprises point clouds with an overlap rate greater than 30%, while 3DLoMatch includes point clouds with a low overlap rate of 10%–30%. 3DMatch contains a total of 62 indoor scenes, of which 46 are used for training, 8 for validation, and the remaining 8 for testing. 3DLoMatch follows the same division protocol as 3DMatch. The KITTI dataset contains a total of 11 sequences of outdoor vehicle driving scenarios, where sequences 0–5 are used for training the model, sequences 6–7 for validation, and sequences 8–10 for testing.
4.2 Metrics
The evaluation metrics used for 3DMatch and KITTI in this paper are selected based on Reference [17]. This setup is employed considering the characteristics of ground truth annotations in the 3DMatch and KITTI datasets, and to facilitate better comparison with state-of-the-art algorithms. We chose the RR (Registration Recall) as the main metric for evaluating the point cloud registration algorithm. This is because the RR can reflect the end-to-end performance of the point cloud registration algorithm.
The RR values for both 3DMatch and KITTI represent the proportion of correctly registered point cloud pairs, though their calculation logics differ. Specifically, for 3DMatch, a registration is deemed correct if the transformation error between two point clouds is less than 0.2 meters. This transformation error is quantified using the Root Mean Square Error (RMSE) of the transformed point cloud pairs, which can be expressed as: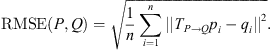 (19)
(19)
Among them, RMSE represents the Root Mean Square Error between the source point cloud P and target point cloud Q after registration. Specifically, n denotes the number of corresponding point pairs, T is the transformation from P to Q, pi refers to points in P, and qi represents their corresponding points in Q.
For 3DMatch, RR is then defined as follows:![Mathematical equation: $$ \mathrm{RR}=\frac{1}{M}\sum_{i=1}^M\left[\left[ {\mathrm{RMSE}}_i<0.2\enspace \mathrm{m}\right]\right]. $$](/articles/jeos/full_html/2025/02/jeos20250045/jeos20250045-eq22.gif) (20)
(20)
Among them, M represents the total number of samples (i.e., point cloud pairs), and RMSE stands for the Root Mean Square Error of registration for the ith group of point clouds.
For KITTI, RR is determined based on the thresholds of relative rotation error and relative translation error, which can be expressed as follows:![Mathematical equation: $$ \mathrm{RR}=\frac{1}{M}\sum_{i=1}^M\left[\left[ {\mathrm{RRE}}_i<5\mathrm{{}^{\circ} }\wedge \enspace {\mathrm{RTE}}_i<0.2\enspace \mathrm{m}\right]\right]. $$](/articles/jeos/full_html/2025/02/jeos20250045/jeos20250045-eq23.gif) (21)
(21)
Among them, M is the total number of point-cloud pairs in the evaluation. RREi denotes the relative rotation error of the ith registered pair, which quantifies the deviation in the estimated rotation transformation between two frames of point clouds, thereby reflecting the algorithm’s accuracy in predicting rotational motion. And RTEi denotes the relative translation error of the ith registered pair, which quantifies the deviation in the estimated translation transformation between two frames of point clouds, thereby reflecting the algorithm’s accuracy in predicting translational motion.
Further clarification is needed regarding the number of sampled point pairs to be set. 3DMatch and 3DLoMatch are indoor scene point clouds generated from data collected by RGB-D sensors. Since these point clouds exhibit relatively regular structures, specifying the number of sampled points allows researchers to investigate how different sparse correspondence relationships affect point cloud registration algorithms in static scenes. The KITTI dataset comprises point clouds captured by LIDAR in outdoor driving scenarios. These point clouds feature irregular structures and cover complex scenes including roads, vehicles, and buildings. Not fixing the number of sampled point pairs allows the model to adapt to the complex structures of outdoor scenes, facilitating the study of the algorithm’s application in outdoor autonomous driving scenarios.
4.3 Implementation details
Experiments were conducted on a workstation equipped with an Intel W5-3425 CPU and an NVIDIA RTX 4090 GPU. The model training environment was configured with Python 3.8.20, PyTorch 2.0.1, and CUDA 11.7. During training, 51 epochs were performed for both the 3DMatch and 3DLoMatch datasets, while 180 epochs were executed for the KITTI dataset. The initial learning rate was set to 1e-4 with a decay coefficient of 0.95: for 3DMatch and 3DLoMatch, it was reduced once per epoch; for KITTI, it was decreased every 4 epochs.
4.4 3DMatch
4.4.1 Result analysis
In the study of point cloud registration, we used RANSAC to estimate the pose transformation relationship between two point clouds. In the experiment, we set different quantities of sampling point pairs, specifically 5000, 2500, 1000, 500, and 250, to assess their impact on registration performance. This approach allows for a systematic evaluation of how varying point pair densities affect the accuracy and efficiency of the registration process across different scales. These values represent the number of point pairs selected in the feature matching stage, among which the k value (i.e., the number of candidate matching points retained for each point) has a direct impact on the total number of matching points. Specifically, for k = 1, the number of corresponding matching points is set to 250, 500, 1000, respectively. For k = 2, the matching points are fixed at 2500. When k = 3, the number of matching points reaches 5000. Without filtering, approximately 6000 matching points can be obtained for each point cloud pair under k = 3. During the experiment, we also investigated the influence of confidence level on the registration results. The data in Tables 1 and 2 indicate that when the RANSAC transformation is performed on the top 5000, 2500, 1000, 500, and 250 points of confidence, the registration recall rate (RR) reaches 91.6% when the number of matching points is 2500. This result leads the comparison algorithm by 1.3–15.4% and represents the SOTA (State of the Art) in the current field. This achievement proves the efficiency and accuracy of the DKGCN-PCR when dealing with complex point cloud registration tasks. Figure 3 shows the registration effects of point clouds with different overlap rates when the number of matching points is 2500.
 |
Figure 3 Registration effects of point clouds with different overlapping ratios. The overlap ratio is calculated relative to the source fragment. |
The evaluation result of the Feature Matching Recall on the 3DMatch.
The evaluation result of the Registration Recall on the 3DMatch.
4.4.2 Ablation study
To validate the effectiveness of the graph convolution module proposed in DKGCN-PCR on the 3DMatch dataset, we conducted ablation experiments, and the results are presented in Tables 1 and 2. In terms of FMR, the DKGCN-PCR demonstrates performance comparable to or superior to baseline. For RR, except for a slight deficit under RANSAC (500) conditions, all other metrics significantly outperform the baseline. Notably, when the number of matching points was set to 2500, DKGCN-PCR achieved a RR of 91.6% on the 3DMatch dataset, outperforming the baseline by 0.9%. This confirms the efficacy of the DKGCN-PCR, particularly when the RANSAC method employs 2500 matching points to complete point cloud registration tasks. Excessive sampled point pairs may introduce more outliers, thereby reducing the accuracy with which the RANSAC algorithm estimates the transformation matrix. In such cases, increasing the number of sampled points will not improve the RR value.
4.5 3DLoMatch
4.5.1 Result analysis
The test results are shown in Tables 3 and 4. From the data, under different sampling scales (such as 5000, 2500, etc.) of the 3DLoMatch dataset, the RR of DKGCN-PCR consistently outperforms most comparison algorithms (such as PerfectMatch, FCGF, etc.). When the number of matching points is 2500, the result is 74.8%, leading the comparison algorithm by 8.6% to 45.8% and reaching the SOTA level in the field. Combined with the low overlap rate feature of 3DLoMatch, this result fully validates the effectiveness of the DKGCN-PCR algorithm. By optimizing the feature extraction module, DKGCN-PCR effectively breaks through the registration bottleneck in low-overlap scenarios, demonstrating strong robustness to sparse correspondence. Figure 3 shows the registration effects of point clouds with different overlap rates when the number of matching points is 2500.
The evaluation result of the Feature Matching Recall on the 3DLoMatch.
The evaluation result of the Registration Recall on the 3DLoMatch.
4.5.2 Ablation study
To verify the effectiveness of the graph convolution module proposed in DKGCN-PCR on the 3DLoMatch dataset (with an overlap rate ranges from 10% to 30%), we conducted ablation experiments, and the results are shown in Tables 3 and 4. In terms of the FMR, the DKGCN-PCR algorithm only performs slightly worse than the baseline when the number of matching points is 250, but achieves performance superiority in the rest (5000, 2500, 1000, 500). Especially when the number of matching points is 2500, the RR result of DKGCN-PCR was 74.8%, leading the baseline by 1.7%. Combined with the low overlap rate scene characteristics of 3DLoMatch, the experiment further verified the robustness of the graph convolution module under sparse correspondence, enabling DKGCN-PCR to adapt to more challenging point cloud registration tasks.
4.6 KITTI
4.6.1 Result analysis
The test results of DKGCN-PCR on the KITTI dataset are shown in Table 5. This algorithm significantly outperforms mainstream methods such as Predator and CoFiNet in the two core metrics of RRE and RTE. It also achieves parity with or exceeds the comparison algorithm in terms of RR. This results fully verify DKGCN-PCR’s accurate estimation ability for the pose of three-dimensional point clouds in complex outdoor environments, such as illumination changes and dynamic target interference.
The evaluation result on the KITTI.
4.6.2 Ablation study
To validate the effectiveness of the graph convolution module proposed in DKGCN-PCR on the KITTI dataset, we conducted ablation experiments. As shown in the experimental data in Table 5, compared with the baseline, this algorithm reduces RRE by 0.04° and RTE by 1.1 cm, while maintaining parity with the baseline in terms of RR. These results demonstrate that the graph convolution module effectively enhances the pose estimation accuracy of the algorithm in complex outdoor scenarios involving dynamic occlusion and illumination changes, ensuring the robustness of the registration process.
5 Conclusion
We study the problem of feature extraction in point cloud registration. Traditional point clouds, due to their irregular structure, lack a well-defined neighborhood relationship, which makes it difficult to effectively obtain point cloud data. This increases the difficulty of feature extraction from the point cloud registration task. To address this challenge, this paper proposes a graph convolution point cloud registration network based on a deformable kernel – DKGCN-PCR. The convolution kernels in this network are adaptively adjusted using the local geometric information and neighborhood features of the point cloud data. The semantic residual module restores lost local information, thereby enhancing the integrity of feature expression. Consider the local features of all vertices to obtain the global features. The feature fusion layer integrates global and local features, updating these fused features to enhance the model’s ability to express complex point cloud data features. Then, the point matching module completes the point correspondence relationship mining based on the features. Subsequently, the RANSAC algorithm is used for pose estimation to solve the transformation parameters (R, T) (rotation, translation). Ultimately, DKGCN-PCR achieves high-quality registration of point clouds in scenarios with low overlap rates and outdoor driving scenarios using the RANSAC transformation estimation.
Funding
This research was funded by the National Natural Science Foundation of China, number 62171467.
Conflicts of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Data availability statement
The point cloud datasets used in this paper are public datasets. For details, please refer to the introduction of the datasets in this paper.
Author contribution statement
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by Yuandong Niu, Juntao Ma and Shuangyou Chen. The first draft of the manuscript was written by Yuandong Niu, Lin Shi, Yunfeng Jiang and Ting An. The format and content of drafts are regulated by Limin Liu, Zhaorui Li and Fuyu Huang. All authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
References
- Servos J, Waslander SL, Multi channel generalized - ICP, in Proceedings of 2014 IEEE International Conference on Robotics and Automation (ICRA) (Hong Kong, China, 2014), pp. 3644–3649. https://doi.org/10.1109/ICRA.2014.6907386. [Google Scholar]
- Yang J, Li H, Campbell D, Jia Y, Go-ICP: A Globally Optimal Solution to 3D ICP Point-Set Registration, IEEE Trans. Pattern Anal. Mach. Intell. 38(11), 2241–2254 (2016). https://doi.org/10.1109/TPAMI.2015.2513405. [Google Scholar]
- Koide K, Yokozuka M, Oishi S, Banno A, Voxelized GICP for fast and accurate 3D point cloud registration, in: Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA) (Xi’an, China, 2021), pp. 11054–11059. https://doi.org/10.1109/ICRA48506.2021.9560835. [Google Scholar]
- Biber P, Strasser W, The normal distributions transform: a new approach to laser scan matching, in: Proceedings of the 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003) (NV, USA, 2003), pp. 2743–2748. https://doi.org/10.1109/IROS.2003.1249285. [Google Scholar]
- Magnusson M, The three-dimensional normal-distributions transform : an efficient representation for registration, surface analysis, and loop detection, in: Ph.D., Örebro University, 2009. [Google Scholar]
- Rusu RB, Blodow N, Beetz M, Fast Point Feature Histograms (FPFH) for 3D registration, in: Proceedings of the 2009 IEEE International Conference on Robotics and Automation (Kobe, Japan, 2009), pp. 3212–3217. https://doi.org/10.1109/ROBOT.2009.5152473. [Google Scholar]
- Salti S, Tombari F, Stefano LD, SHOT: Unique signatures of histograms for surface and texture description, Comput. Vis. Image. Und. 125, 251–264 (2015). https://doi.org/10.1016/j.cviu.2014.04.011. [Google Scholar]
- Rusu RB, Bradski G, Thibaux R, Hsu J, Fast 3D recognition and pose using the Viewpoint Feature Histogram, in: Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (Taipei, Taiwan, 2010), pp. 2155–2162. https://doi.org/10.1109/IROS.2010.5651280. [Google Scholar]
- Aoki Y, Goforth H, Srivatsan RA, Lucey S, PointNetLK: Robust and Efficient Point Cloud Registration Using PointNet, in: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (CA, USA, 2019), pp. 7156–7165. https://doi.org/10.1109/CVPR.2019.00733. [Google Scholar]
- Lu W, Wan G, Zhou Y, Fu X, Yuan P, Song S, DeepVCP: An end-to-end deep neural network for point cloud registration, in: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (Seoul, Korea (South), 2019), 12–21. https://doi.org/10.1109/ICCV.2019.00010. [Google Scholar]
- Wang Y, Solomon J, Deep closest point: learning representations for point cloud registration, in: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (Seoul, Korea (South), 2019), 3522–3531. https://doi.org/10.1109/ICCV.2019.00362. [Google Scholar]
- Wang Y, Solomon J, PRNet: Self-Supervised Learning for Partial-to-Partial Registration, in: Proceedings of Neural Information Processing Systems (NIPS) (NY, USA, 2019), pp. 8814–8826. https://dl.acm.org/doi/abs/10.5555/3295222.3295263. [Google Scholar]
- Li J, Zhang C, Xu Z, Zhou H, Zhang C, Iterative distance-aware similarity matrix convolution with mutual-supervised point elimination for efficient point cloud registration, in: Proceedings of 16th European Conference on Computer Vision (ECCV2020) (Glasgow, UK, 2020), pp. 378–394. https://doi.org/10.1007/978-3-030-58586-0_23. [Google Scholar]
- Yew ZJ, Lee GH, RPM-Net: Robust Point Matching Using Learned Features, in Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (WA, USA, 2020), pp. 11821–11830. https://doi.org/10.1109/CVPR42600.2020.01184. [Google Scholar]
- Pais GD, Ramalingam S, Govindu VM, Nascimento JC, Chellappa R, Miraldo P, 3DRegNet: A Deep Neural Network for 3D Point Registration, in: Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (WA, USA, 2020), pp. 7191–7201. https://doi.org/10.1109/CVPR42600.2020.00722. [Google Scholar]
- Yang J, Zhang X, Wang P, Guo Y, Sun K, Wu Q, Zhang S, Zhang Y, MAC: Maximal Cliques for 3D Registration, IEEE Trans. Pattern Anal. Mach. Intell. 46(12), 10645–10662 (2024). https://doi.org/10.1109/TPAMI.2024.3442911. [Google Scholar]
- Huang S, Gojcic Z, Usvyatsov M, Wieser M, Schindler K, PREDATOR: Registration of 3D Point Clouds with Low Overlap, in: Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA (2021), pp. 4265–4274. https://doi.org/10.1109/CVPR46437.2021.00425. [Google Scholar]
- Ao S, Hu Q, Wang H, Xu K, Guo Y, BUFFER: Balancing Accuracy, Efficiency, and Generalizability in Point Cloud Registration, in: Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (BC, Canada, 2023), pp. 1255–1264. https://doi.org/10.1109/CVPR52729.2023.00127. [Google Scholar]
- Charles RQ, Su H, Kaichun M, Guibas LJ, PointNet: Deep learning on point sets for 3D classification and segmentation, in: Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (HI, USA, 2017), pp. 77–85. https://doi.org/10.1109/CVPR.2017.16. [Google Scholar]
- Charles RQ, Yi L, Hao S, Leonidas JG, PointNet++: deep hierarchical feature learning on point sets in a metric space, in: Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17) (NY, USA, 2017), pp. 5105–5114. https://dl.acm.org/doi/abs/10.5555/3295222.3295263. [Google Scholar]
- Wang Y, Sun Y, Liu Z, Sarma S, Bronstein M, Solomon J, Dynamic graph CNN for learning on point clouds, ACM Trans. Graph. 38(5), 1–12 (2019). https://doi.org/10.1145/3326362. [Google Scholar]
- Xia T, Lin J, Li Y, Feng J, Hui P, Sun F, Guo D, Jin D, 3DGCN: 3-Dimensional Dynamic Graph Convolutional Network for Citywide Crowd Flow Prediction, ACM Trans. Knowl. Discov. Data. 15(6), 1–21 (2021). https://doi.org/10.1145/3451394. [Google Scholar]
- Xu G, Pang Y, Bai Z, Wang Y, Lu Z, A fast point clouds registration algorithm for laser scanners, Appl. Sci. 11, 3426 (2021). https://doi.org/10.3390/app11083426. [Google Scholar]
- Gojcic Z, Zhou C, Wegner JD, Wieser A, The perfect match: 3d point cloud matching with smoothed densities, in Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (CA, USA, 2019), pp. 5540–5549. https://doi.org/10.1109/CVPR.2019.00569. [Google Scholar]
- Choy C, Park J, Koltun V, Fully Convolutional Geometric Features, in: Proceedings of 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (Seoul, Korea (South), 2019), pp. 8957–8965. https://doi.org/10.1109/ICCV.2019.00905. [Google Scholar]
- Bai X, Luo Z, Zhou L, Fu H, Quan L, Tai C-L, D3Feat: Joint Learning of Dense Detection and Description of 3D Local Features, in: Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (WA, USA, 2020), pp. 6358–6366. https://doi.org/10.1109/CVPR42600.2020.00639. [Google Scholar]
- Ao S, Hu Q, Yang B, Markham A, Guo Y, SpinNet: Learning a General Surface Descriptor for 3D Point Cloud Registration, in: Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (TN, USA, 2021), pp. 11748–11757. https://doi.org/10.1109/CVPR46437.2021.01158. [Google Scholar]
- Wang H, Liu Y, Dong Z, Wang W, You only hypothesize once: point cloud registration with rotation-equivariant descriptors, in: Proceedings of 30th ACM International Conference on Multimedia (MM ‘22) (NY, USA, 2022), pp. 1630–1641. https://doi.org/10.1145/3503161.3548023. [Google Scholar]
- Yu H, Li F, Saleh M, Busam B, Ilic S, CoFiNet: reliable coarse-to-fine correspondences for robust point cloud registration, in: Proceedings of 35th International Conference on Neural Information Processing Systems (NIPS ‘21) (NY, USA, 2021), pp. 23872-23884. https://dl.acm.org/doi/10.5555/3540261.3542089. [Google Scholar]
- Yew ZJ, Lee GH, 3Dfeat-net: Weakly supervised local 3d features for point cloud registration, in: Proceedings of 15th European Conference on Computer Vision (ECCV 2018) (Munich, Germany, 2018), pp. 630–646. https://doi.org/10.1007/978-3-030-01267-0_37. [Google Scholar]
All Tables
All Figures
|
Figure 1 Firstly, perform feature extraction on the two groups of input point clouds to obtain the feature representations F P and F Q respectively. Then, the point matching module completes the point correspondence relationship mining based on the features. Subsequently, the RANSAC algorithm is used for pose estimation to solve the transformation parameters (R, T) (rotation, translation). Finally, the 3D registration of the two groups of point clouds was completed based on this transformation to achieve point cloud alignment. |
| In the text | |
|
Figure 2 Schematic diagrams of 3D convolutional neural network (a) and 3D graph convolutional network (b). |
| In the text | |
|
Figure 3 Registration effects of point clouds with different overlapping ratios. The overlap ratio is calculated relative to the source fragment. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.