Fig. 4
Download original image
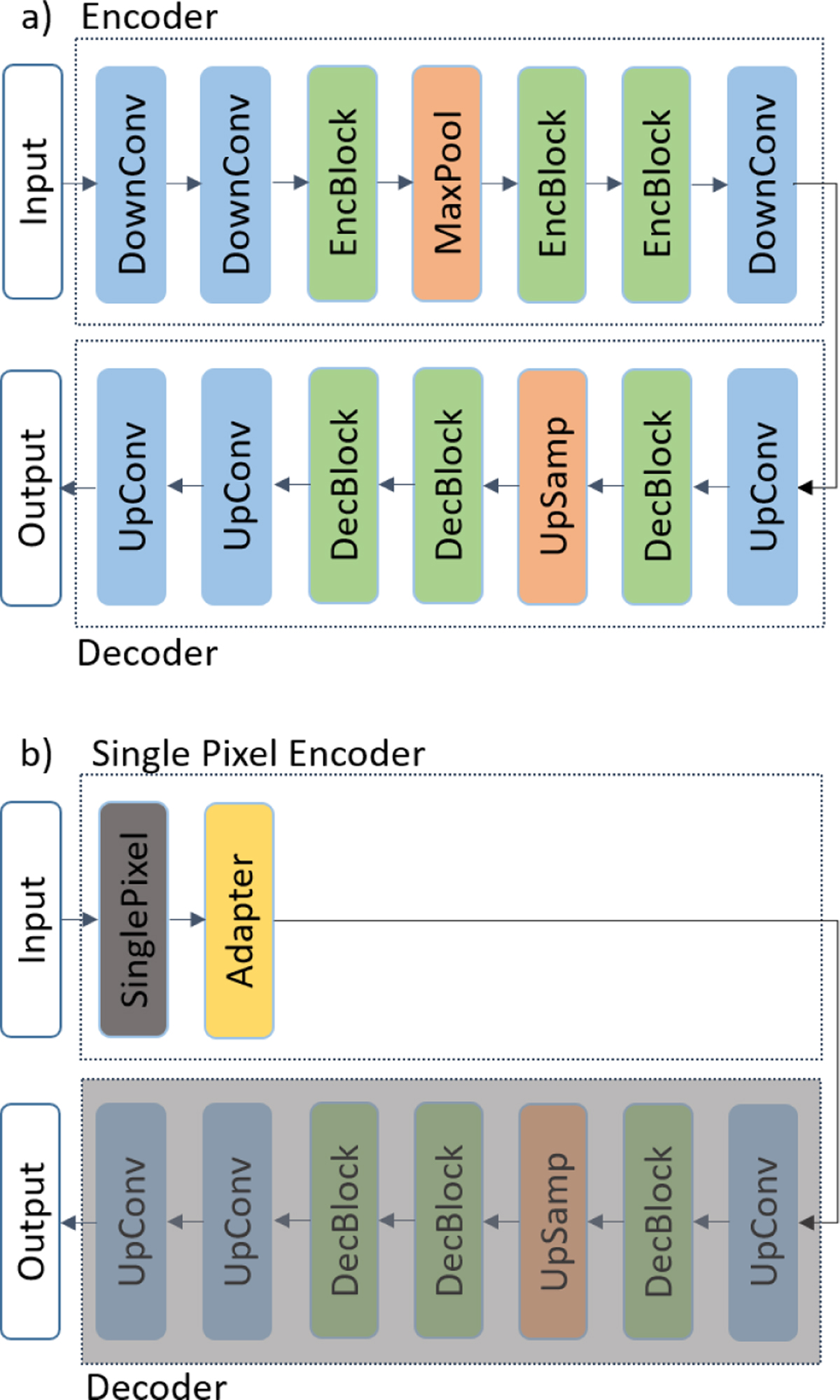
Schematic drawing of the network architecture of the autoencoder (a) as well as the single-pixel-decoder (b) for 6.25% compression ratio. For lower compression ratios, a down/up-convolutional block as well as an encoder block was added. The encoder/decoder block consists of two convolutional layers with kernel size 3 and 128 filters each as well as a skip connection. As activation function we used LeakyRelu. The weights of the decoder part of the single-pixel-decoder are shared with the autoencoder network and not retrained. DownConv: Convolutional layer with stride 2, EncBlock/DecBlock: Encoder/Decoder block, MaxPool: Maximum pooling layer, UpConv: Convolutional layer followed by a transpose convolutional layer with stride 2, UpSamp: Upsampling layer.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.